-
 靜安區銷售驗證模型大概是
靜安區銷售驗證模型大概是模型驗證:確保AI系統準確性與可靠性的關鍵步驟在人工智能(AI)領域,模型驗證是確保機器學習模型在實際應用中表現良好、準確且可靠的關鍵環節。隨著AI技術的飛速發展,從自動駕駛汽車到醫療診斷系統,各種AI應用正日益融入我們的日常生活。然而,這些應用的準確性和安全性直接關系到人們的生命財產安全,因此,對模型進行嚴格的驗證顯得尤為重要。一、模型驗證的定義與目的模型驗證是指通過一系列方法和流程,系統地評估機器學習模型的性能、準確性、魯棒性、公平性以及對未見數據的泛化能力。其**目的在于:交叉驗證:如果數據量較小,可以采用交叉驗證(如K折交叉驗證)來更評估模型性能。靜安區銷售驗證模型大概是光刻模型包含光...
-
 長寧區銷售驗證模型優勢
長寧區銷售驗證模型優勢選擇比較好模型:在多個候選模型中,驗證可以幫助我們選擇比較好的模型,從而提高**終應用的效果。提高模型的可信度:通過嚴格的驗證過程,我們可以增強對模型結果的信心,尤其是在涉及重要決策的領域,如醫療、金融等。二、常用的模型驗證方法訓練集與測試集劃分:將數據集分為訓練集和測試集,通常采用70%作為訓練集,30%作為測試集。模型在訓練集上進行訓練,然后在測試集上進行評估。交叉驗證:交叉驗證是一種更為穩健的驗證方法。常見的有K折交叉驗證,將數據集分為K個子集,輪流使用其中一個子集作為測試集,其余作為訓練集。這樣可以多次評估模型性能,減少偶然性。使用驗證集評估模型的性能,常用的評估指標包括準確率、召回率...
-
崇明區銷售驗證模型優勢
性能指標:根據任務的不同,選擇合適的性能指標進行評估。例如:分類任務:準確率、精確率、召回率、F1-score、ROC曲線和AUC值等。回歸任務:均方誤差(MSE)、均***誤差(MAE)、R2等。學習曲線:繪制學習曲線可以幫助理解模型在不同訓練集大小下的表現,幫助判斷模型是否過擬合或欠擬合。超參數調優:使用網格搜索(Grid Search)或隨機搜索(Random Search)等方法對模型的超參數進行調優,以找到比較好參數組合。模型比較:將不同模型的性能進行比較,選擇表現比較好的模型。外部驗證:如果可能,使用**的外部數據集對模型進行驗證,以評估其在真實場景中的表現。訓練集與測試集劃分:將...
-
 奉賢區智能驗證模型熱線
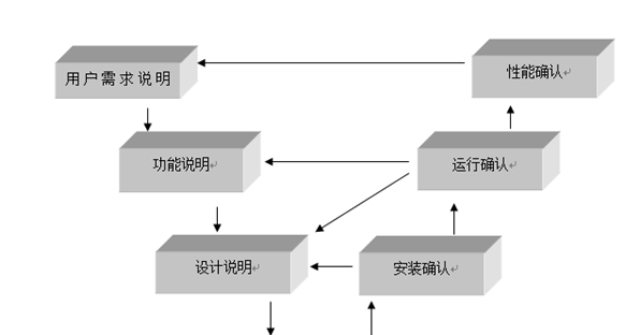
奉賢區智能驗證模型熱線在進行模型校準時要依次確定用于校準的參數和關鍵圖案,并建立校準過程的評估標準。校準參數和校準圖案的選擇結果直接影響校準后光刻膠模型的準確性和校準的運行時間,如圖4所示 [4]。準參數包括曝光、烘烤、顯影等工藝參數和光酸擴散長度等光刻膠物理化學參數,如圖5所示 [5]。關鍵圖案的選擇方式主要包含基于經驗的選擇方式、隨機選擇方式、根據圖案密度等特性選擇的方式、主成分分析選擇方式、高維空間映射的選擇方式、基于復雜數學模型的自動選擇方式、頻譜聚類選擇方式、基于頻譜覆蓋率的選擇方式等 [2]。校準過程的評估標準通常使用模型預測值與晶圓測量值之間的偏差的均方根(RMS)。驗證模型是機器學習和統計建模中的一...
-
松江區優良驗證模型優勢
驗證模型:確保預測準確性與可靠性的關鍵步驟在數據科學和機器學習領域,構建模型只是整個工作流程的一部分。一個模型的性能不僅*取決于其設計時的巧妙程度,更在于其在實際應用中的表現。因此,驗證模型成為了一個至關重要的環節,它直接關系到模型能否有效解決實際問題,以及能否被信任并部署到生產環境中。本文將深入探討驗證模型的重要性、常用方法以及面臨的挑戰,旨在為數據科學家和機器學習工程師提供一份實用的指南。一、驗證模型的重要性評估性能:驗證模型的首要目的是評估其在未見過的數據上的表現,這有助于了解模型的泛化能力,即模型對新數據的預測準確性。由于模型檢測可以自動執行,并能在系統不滿足性質時提供反例路徑,因此在...
-
金山區直銷驗證模型信息中心
三、面臨的挑戰與應對策略數據不平衡:當數據集中各類別的樣本數量差異很大時,驗證模型的準確性可能會受到影響。解決方法包括使用重采樣技術(如過采樣、欠采樣)或應用合成少數類過采樣技術(SMOTE)來平衡數據集。時間序列數據的特殊性:對于時間序列數據,簡單的隨機劃分可能導致數據泄露,即驗證集中包含了訓練集中未來的信息。此時,應采用時間分割法,確保訓練集和驗證集在時間線上完全分離。模型解釋性:在追求模型性能的同時,也要考慮模型的解釋性,尤其是在需要向非技術人員解釋預測結果的場景下。通過集成學習中的bagging、boosting方法或引入可解釋性更強的模型(如決策樹、線性回歸)來提高模型的可解釋性。根...
-
 靜安區優良驗證模型熱線
靜安區優良驗證模型熱線在產生模型分析(即 MG 類模型)中,模型應用者先提出一個或多個基本模型,然后檢查這些模型是否擬合樣本數據,基于理論或樣本數據,分析找出模型擬合不好的部分,據此修改模型,并通過同一的樣本數據或同類的其他樣本數據,去檢查修正模型的擬合程度。這樣一個整個的分析過程的目的就是要產生一個比較好的模型。因此,結構方程除可用作驗證模型和比較不同的模型外,也可以用作評估模型及修正模型。一些結構方程模型的應用人員都是先從一個預設的模型開始,然后將此模型與所掌握的樣本數據相互印證。如果發現預設的模型與樣本數據擬合的并不是很好,那么就將預設的模型進行修改,然后再檢驗,不斷重復這么一個過程,直至**終獲得一個模型應...
-
嘉定區直銷驗證模型便捷
在給定的建模樣本中,拿出大部分樣本進行建模型,留小部分樣本用剛建立的模型進行預報,并求這小部分樣本的預報誤差,記錄它們的平方加和。這個過程一直進行,直到所有的樣本都被預報了一次而且*被預報一次。把每個樣本的預報誤差平方加和,稱為PRESS(predicted Error Sum of Squares)。交叉驗證的基本思想是把在某種意義下將原始數據(dataset)進行分組,一部分做為訓練集(train set),另一部分做為驗證集(validation set or test set),首先用訓練集對分類器進行訓練,再利用驗證集來測試訓練得到的模型(model),以此來做為評價分類器的性能指標...
-
浦東新區直銷驗證模型要求
指標數目一般要求因子的指標數目至少為3個。在探索性研究或者設計問卷的初期,因子指標的數目可以適當多一些,預試結果可以根據需要刪除不好的指標。當少于3個或者只有1個(因子本身是顯變量的時候,如收入)的時候,有專門的處理辦法。數據類型絕大部分結構方程模型是基于定距、定比、定序數據計算的。但是軟件(如Mplus)可以處理定類數據。數據要求要有足夠的變異量,相關系數才能顯而易見。如樣本中的數學成績非常接近(如都是95分左右),則數學成績差異大部分是測量誤差引起的,則數學成績與其它變量之間的相關就不***。記錄模型驗證過程中的所有步驟、參數設置、性能指標等,以便后續復現和審計。浦東新區直銷驗證模型要求在...
-
長寧區智能驗證模型咨詢熱線
確保準確性:驗證模型在特定任務上的預測或分類準確性是否達到預期。提升魯棒性:檢查模型面對噪聲數據、異常值或對抗性攻擊時的穩定性。公平性考量:確保模型對不同群體的預測結果無偏見,避免算法歧視。泛化能力評估:測試模型在未見過的數據上的表現,以預測其在真實世界場景中的效能。二、模型驗證的主要方法交叉驗證:將數據集分成多個部分,輪流用作訓練集和測試集,以***評估模型的性能。這種方法有助于減少過擬合的風險,提供更可靠的性能估計。選擇模型:在多個候選模型中,驗證可以幫助我們選擇模型,從而提高應用的效果。長寧區智能驗證模型咨詢熱線驗證模型是機器學習過程中的一個關鍵步驟,旨在評估模型的性能,確保其在實際應用...
-
 松江區優良驗證模型大概是
松江區優良驗證模型大概是留一交叉驗證(LOOCV):這是K折交叉驗證的一種特殊情況,其中K等于樣本數量。每次只留一個樣本作為測試集,其余作為訓練集。這種方法適用于小數據集,但計算成本較高。自助法(Bootstrap):通過有放回地從原始數據集中抽取樣本來構建多個訓練集和測試集。這種方法可以有效利用小樣本數據。三、驗證過程中的注意事項數據泄露:在模型訓練和驗證過程中,必須確保訓練集和測試集之間沒有重疊,以避免數據泄露導致的性能虛高。選擇合適的評估指標:根據具體問題選擇合適的評估指標,如分類問題中的準確率、召回率、F1-score等,回歸問題中的均方誤差(MSE)、均方根誤差(RMSE)等。訓練集與測試集劃分:將數據集分...
-
上海口碑好驗證模型供應
考慮模型復雜度:在驗證過程中,需要平衡模型的復雜度與性能。過于復雜的模型可能會導致過擬合,而過于簡單的模型可能無法捕捉數據中的重要特征。多次驗證:為了提高結果的可靠性,可以進行多次驗證并取平均值,尤其是在數據集較小的情況下。結論模型驗證是機器學習流程中不可或缺的一部分。通過合理的驗證方法,我們可以確保模型的性能和可靠性,從而在實際應用中取得更好的效果。在進行模型驗證時,務必注意數據的劃分、評估指標的選擇以及模型復雜度的控制,以確保驗證結果的準確性和有效性。模型驗證是指測定標定后的交通模型對未來數據的預測能力(即可信程度)的過程。上海口碑好驗證模型供應構建模型:在訓練集上構建模型,并進行必要的調...
-
浦東新區正規驗證模型介紹
選擇合適的評估指標:根據具體的應用場景和需求,選擇合適的評估指標來評估模型的性能。常用的評估指標包括準確率、召回率、F1分數等。多次驗證:為了獲得更可靠的驗證結果,可以進行多次驗證并取平均值作為**終評估結果。考慮模型復雜度:在驗證過程中,需要權衡模型的復雜度和性能。過于復雜的模型可能導致過擬合,而過于簡單的模型可能無法充分捕捉數據中的信息。綜上所述,模型驗證是確保模型性能穩定、準確的重要步驟。通過選擇合適的驗證方法、遵循規范的驗證步驟和注意事項,可以有效地評估和改進模型的性能。擬合度分析,類似于模型標定,校核觀測值和預測值的吻合程度。浦東新區正規驗證模型介紹簡單而言,與傳統的回歸分析不同,結...
-
浦東新區口碑好驗證模型信息中心
選擇合適的評估指標:根據具體的應用場景和需求,選擇合適的評估指標來評估模型的性能。常用的評估指標包括準確率、召回率、F1分數等。多次驗證:為了獲得更可靠的驗證結果,可以進行多次驗證并取平均值作為**終評估結果。考慮模型復雜度:在驗證過程中,需要權衡模型的復雜度和性能。過于復雜的模型可能導致過擬合,而過于簡單的模型可能無法充分捕捉數據中的信息。綜上所述,模型驗證是確保模型性能穩定、準確的重要步驟。通過選擇合適的驗證方法、遵循規范的驗證步驟和注意事項,可以有效地評估和改進模型的性能。模型在訓練集上進行訓練,然后在測試集上進行評估。浦東新區口碑好驗證模型信息中心確保準確性:驗證模型在特定任務上的預測...
-
浦東新區自動驗證模型優勢
防止過擬合:通過對比訓練集和驗證集上的性能,可以識別模型是否存在過擬合現象(即模型在訓練數據上表現過好,但在新數據上表現不佳)。參數調優:驗證集還為模型參數的選擇提供了依據,幫助找到比較好的模型配置,以達到比較好的預測效果。增強可信度:經過嚴格驗證的模型在部署后更能贏得用戶的信任,特別是在醫療、金融等高風險領域。二、驗證模型的常用方法交叉驗證:K折交叉驗證:將數據集隨機分成K個子集,每次用K-1個子集作為訓練集,剩余的一個子集作為驗證集,重復K次,每次選擇不同的子集作為驗證集,**終評估結果為K次驗證的平均值。回歸任務:均方誤差(MSE)、誤差(MAE)、R2等。浦東新區自動驗證模型優勢確保準...
-
徐匯區自動驗證模型咨詢熱線
模型檢驗是確定模型的正確性、有效性和可信性的研究與測試過程。具體是指對一個給定的軟件或硬件系統建立模型后,需要對其進行行為上的可信性、動態性能的有效性、實驗數據、可測數據的逼近精度、研究自的的可達性等問題的檢驗,以驗證所建立的模型是否能夠真實反喚實際系統,或者說能夠與真實系統達到較高精度的性能相關技術。 [2]模型檢驗在多個領域都有廣泛的應用,它在軟件工程中用于驗證軟件系統的正確性和可靠性,在硬件設計中確保硬件模型符合設計規范,而在數據分析與機器學習領域則評估模型的擬合效果和泛化能力。此外,在心理學與社會科學領域,模型檢驗通過驗證性因子分析等方法檢驗量表的結構效度,確保研究工具的可靠性和有效性...
-
崇明區智能驗證模型熱線
模型驗證是指測定標定后的交通模型對未來數據的預測能力(即可信程度)的過程。根據具體要求和可能,可用的驗證方法有:①靈敏度分析,著重于確保模型預測值不會背離期望值,如相差太大,可判斷應調整前者還是后者,另外還能確保模型與假定條件充分協調。②擬合度分析,類似于模型標定,校核觀測值和預測值的吻合程度。 [1]因預測的規劃年數據不可能在現場得到,就要借用現狀或過去的觀測值,但需注意不能重復使用標定服務的觀測數據。具體做法有兩種:一是將觀測數據按時序分成前后兩組,前組用于標定,后組用于驗證;二是將同時段的觀測數據隨機地分為兩部分,將用***部分數據標定后的模型計算值同第二部分數據相擬合。比較測試集上的性...
-
金山區智能驗證模型優勢
外部驗證:外部驗證是將構建好的比較好預測模型在全新的數據集中進行評估,以評估模型的通用性和預測性能。如果模型在原始數據中過度擬合,那么它在其他群體中可能就表現不佳。因此,外部驗證是檢驗模型泛化能力的重要手段。三、模型驗證的步驟模型驗證通常包括以下步驟:準備數據集:收集并準備用于驗證的數據集,包括訓練集、驗證集和測試集。確保數據集的質量、完整性和代表性。選擇驗證方法:根據具體的應用場景和需求,選擇合適的驗證方法。避免過擬合:確保模型在驗證集和測試集上的性能穩定,避免模型在訓練集上表現過好而在未見數據上表現不佳。金山區智能驗證模型優勢在給定的建模樣本中,拿出大部分樣本進行建模型,留小部分樣本用剛建...
-
黃浦區口碑好驗證模型便捷
結構方程模型是基于變量的協方差矩陣來分析變量之間關系的一種統計方法,是多元數據分析的重要工具。很多心理、教育、社會等概念,均難以直接準確測量,這種變量稱為潛變量(latent variable),如智力、學習動機、家庭社會經濟地位等等。因此只能用一些外顯指標(observable indicators),去間接測量這些潛變量。傳統的統計方法不能有效處理這些潛變量,而結構方程模型則能同時處理潛變量及其指標。傳統的線性回歸分析容許因變量存在測量誤差,但是要假設自變量是沒有誤差的。分類任務:準確率、精確率、召回率、F1-score、ROC曲線和AUC值等。黃浦區口碑好驗證模型便捷選擇比較好模型:在多...
-
金山區直銷驗證模型熱線
在驗證模型(SC)的應用中,從應用者的角度來看,對他所分析的數據只有一個模型是**合理和比較符合所調查數據的。應用結構方程建模去分析數據的目的,就是去驗證模型是否擬合樣本數據,從而決定是接受還是拒絕這個模型。這一類的分析并不太多,因為無論是接受還是拒絕這個模型,從應用者的角度來說,還是希望有更好的選擇。在選擇模型(AM)分析中,結構方程模型應用者提出幾個不同的可能模型(也稱為替代模型或競爭模型),然后根據各個模型對樣本數據擬合的優劣情況來決定哪個模型是**可取的。這種類型的分析雖然較驗證模型多,但從應用的情況來看,即使模型應用者得到了一個**可取的模型,但仍然是要對模型做出不少修改的,這樣就成...
-
青浦區自動驗證模型介紹
驗證模型的重要性及其方法在機器學習和數據科學的領域中,模型驗證是一個至關重要的步驟。它不僅可以幫助我們評估模型的性能,還能確保模型在實際應用中的可靠性和有效性。本文將探討模型驗證的重要性、常用的方法以及在驗證過程中需要注意的事項。一、模型驗證的重要性評估模型性能:通過驗證,我們可以了解模型在未見數據上的表現。這對于判斷模型的泛化能力至關重要。防止過擬合:過擬合是指模型在訓練數據上表現良好,但在測試數據上表現不佳。驗證過程可以幫助我們識別和減少過擬合的風險。分類任務:準確率、精確率、召回率、F1-score、ROC曲線和AUC值等。青浦區自動驗證模型介紹考慮模型復雜度:在驗證過程中,需要平衡模型...
-
靜安區優良驗證模型價目
模型驗證是指測定標定后的交通模型對未來數據的預測能力(即可信程度)的過程。根據具體要求和可能,可用的驗證方法有:①靈敏度分析,著重于確保模型預測值不會背離期望值,如相差太大,可判斷應調整前者還是后者,另外還能確保模型與假定條件充分協調。②擬合度分析,類似于模型標定,校核觀測值和預測值的吻合程度。 [1]因預測的規劃年數據不可能在現場得到,就要借用現狀或過去的觀測值,但需注意不能重復使用標定服務的觀測數據。具體做法有兩種:一是將觀測數據按時序分成前后兩組,前組用于標定,后組用于驗證;二是將同時段的觀測數據隨機地分為兩部分,將用***部分數據標定后的模型計算值同第二部分數據相擬合。交叉驗證:如果數...
-
崇明區正規驗證模型介紹
實驗條件的對標首先,要將模型中的實驗設置與實際的實驗條件進行對標,包含各項工藝參數和測試圖案的信息。其中工藝參數包含光刻機信息、照明條件、光刻涂層設置等信息。測試圖案要基于設計規則來確定,同時要確保測試圖案的幾何特性具有一定的代表性。光刻膠形貌的測量進行光刻膠形貌測量時,通常需要利用掃描電子顯微鏡(SEM)收集每個聚焦能量矩陣(FEM)自上而下的CD、光刻膠截面輪廓、光刻膠高度和側壁角 [3],并將其用于光刻膠模型校準,如圖3所示。很多情況下,可以把模型檢測和各種抽象與歸納原則結合起來驗證非有窮狀態系統(如實時系統)。崇明區正規驗證模型介紹留一交叉驗證(LOOCV):當數據集非常小時,可以使用...
-
金山區智能驗證模型供應
交叉驗證有時也稱為交叉比對,如:10折交叉比對 [2]。Holdout 驗證常識來說,Holdout 驗證并非一種交叉驗證,因為數據并沒有交叉使用。 隨機從**初的樣本中選出部分,形成交叉驗證數據,而剩余的就當做訓練數據。 一般來說,少于原本樣本三分之一的數據被選做驗證數據。K-fold cross-validationK折交叉驗證,初始采樣分割成K個子樣本,一個單獨的子樣本被保留作為驗證模型的數據,其他K-1個樣本用來訓練。交叉驗證重復K次,每個子樣本驗證一次,平均K次的結果或者使用其它結合方式,**終得到一個單一估測。這個方法的優勢在于,同時重復運用隨機產生的子樣本進行訓練和驗證,每次的結...
-
浦東新區銷售驗證模型咨詢熱線
確保準確性:驗證模型在特定任務上的預測或分類準確性是否達到預期。提升魯棒性:檢查模型面對噪聲數據、異常值或對抗性攻擊時的穩定性。公平性考量:確保模型對不同群體的預測結果無偏見,避免算法歧視。泛化能力評估:測試模型在未見過的數據上的表現,以預測其在真實世界場景中的效能。二、模型驗證的主要方法交叉驗證:將數據集分成多個部分,輪流用作訓練集和測試集,以***評估模型的性能。這種方法有助于減少過擬合的風險,提供更可靠的性能估計。留一交叉驗證(LOOCV):每次只留一個樣本作為測試集,其余樣本作為訓練集,適用于小數據集。浦東新區銷售驗證模型咨詢熱線選擇比較好模型:在多個候選模型中,驗證可以幫助我們選擇比...
-
楊浦區正規驗證模型優勢
在產生模型分析(即 MG 類模型)中,模型應用者先提出一個或多個基本模型,然后檢查這些模型是否擬合樣本數據,基于理論或樣本數據,分析找出模型擬合不好的部分,據此修改模型,并通過同一的樣本數據或同類的其他樣本數據,去檢查修正模型的擬合程度。這樣一個整個的分析過程的目的就是要產生一個比較好的模型。因此,結構方程除可用作驗證模型和比較不同的模型外,也可以用作評估模型及修正模型。一些結構方程模型的應用人員都是先從一個預設的模型開始,然后將此模型與所掌握的樣本數據相互印證。如果發現預設的模型與樣本數據擬合的并不是很好,那么就將預設的模型進行修改,然后再檢驗,不斷重復這么一個過程,直至**終獲得一個模型應...
-
普陀區智能驗證模型優勢
在進行模型校準時要依次確定用于校準的參數和關鍵圖案,并建立校準過程的評估標準。校準參數和校準圖案的選擇結果直接影響校準后光刻膠模型的準確性和校準的運行時間,如圖4所示 [4]。準參數包括曝光、烘烤、顯影等工藝參數和光酸擴散長度等光刻膠物理化學參數,如圖5所示 [5]。關鍵圖案的選擇方式主要包含基于經驗的選擇方式、隨機選擇方式、根據圖案密度等特性選擇的方式、主成分分析選擇方式、高維空間映射的選擇方式、基于復雜數學模型的自動選擇方式、頻譜聚類選擇方式、基于頻譜覆蓋率的選擇方式等 [2]。校準過程的評估標準通常使用模型預測值與晶圓測量值之間的偏差的均方根(RMS)。繪制學習曲線可以幫助理解模型在不同...
-
浦東新區優良驗證模型供應
選擇比較好模型:在多個候選模型中,驗證可以幫助我們選擇比較好的模型,從而提高**終應用的效果。提高模型的可信度:通過嚴格的驗證過程,我們可以增強對模型結果的信心,尤其是在涉及重要決策的領域,如醫療、金融等。二、常用的模型驗證方法訓練集與測試集劃分:將數據集分為訓練集和測試集,通常采用70%作為訓練集,30%作為測試集。模型在訓練集上進行訓練,然后在測試集上進行評估。交叉驗證:交叉驗證是一種更為穩健的驗證方法。常見的有K折交叉驗證,將數據集分為K個子集,輪流使用其中一個子集作為測試集,其余作為訓練集。這樣可以多次評估模型性能,減少偶然性。很多情況下,可以把模型檢測和各種抽象與歸納原則結合起來驗證...
-
松江區銷售驗證模型價目
基準測試:使用公開的標準數據集和評價指標,將模型性能與已有方法進行對比,快速了解模型的優勢與不足。A/B測試:在實際應用中同時部署兩個或多個版本的模型,通過用戶反饋或業務指標來評估哪個模型表現更佳。敏感性分析:改變模型輸入或參數設置,觀察模型輸出的變化,以評估模型對特定因素的敏感度。對抗性攻擊測試:專門設計輸入數據以欺騙模型,檢測模型對這類攻擊的抵抗能力。三、面臨的挑戰與應對策略盡管模型驗證至關重要,但在實踐中仍面臨諸多挑戰:數據偏差:真實世界數據往往存在偏差,如何獲取***、代表性的數據集是一大難題。繪制學習曲線可以幫助理解模型在不同訓練集大小下的表現,幫助判斷模型是否過擬合或欠擬合。松江區...
-
嘉定區優良驗證模型大概是
模型檢測(model checking),是一種自動驗證技術,由Clarke和Emerson以及Quelle和Sifakis提出,主要通過顯式狀態搜索或隱式不動點計算來驗證有窮狀態并發系統的模態/命題性質。由于模型檢測可以自動執行,并能在系統不滿足性質時提供反例路徑,因此在工業界比演繹證明更受推崇。盡管限制在有窮系統上是一個缺點,但模型檢測可以應用于許多非常重要的系統,如硬件控制器和通信協議等有窮狀態系統。很多情況下,可以把模型檢測和各種抽象與歸納原則結合起來驗證非有窮狀態系統(如實時系統)。數據分布一致性:確保訓練集、驗證集和測試集的數據分布一致,以反映模型在實際應用中的性能。嘉定區優良驗證...