虹口區優良驗證模型咨詢熱線
在給定的建模樣本中,拿出大部分樣本進行建模型,留小部分樣本用剛建立的模型進行預報,并求這小部分樣本的預報誤差,記錄它們的平方加和。這個過程一直進行,直到所有的樣本都被預報了一次而且*被預報一次。把每個樣本的預報誤差平方加和,稱為PRESS(predicted Error Sum of Squares)。交叉驗證的基本思想是把在某種意義下將原始數據(dataset)進行分組,一部分做為訓練集(train set),另一部分做為驗證集(validation set or test set),首先用訓練集對分類器進行訓練,再利用驗證集來測試訓練得到的模型(model),以此來做為評價分類器的性能指標。分類任務:準確率、精確率、召回率、F1-score、ROC曲線和AUC值等。虹口區優良驗證模型咨詢熱線
考慮模型復雜度:在驗證過程中,需要平衡模型的復雜度與性能。過于復雜的模型可能會導致過擬合,而過于簡單的模型可能無法捕捉數據中的重要特征。多次驗證:為了提高結果的可靠性,可以進行多次驗證并取平均值,尤其是在數據集較小的情況下。結論模型驗證是機器學習流程中不可或缺的一部分。通過合理的驗證方法,我們可以確保模型的性能和可靠性,從而在實際應用中取得更好的效果。在進行模型驗證時,務必注意數據的劃分、評估指標的選擇以及模型復雜度的控制,以確保驗證結果的準確性和有效性。崇明區優良驗證模型要求防止過擬合:過擬合是指模型在訓練數據上表現良好,但在測試數據上表現不佳。
指標數目一般要求因子的指標數目至少為3個。在探索性研究或者設計問卷的初期,因子指標的數目可以適當多一些,預試結果可以根據需要刪除不好的指標。當少于3個或者只有1個(因子本身是顯變量的時候,如收入)的時候,有專門的處理辦法。數據類型絕大部分結構方程模型是基于定距、定比、定序數據計算的。但是軟件(如Mplus)可以處理定類數據。數據要求要有足夠的變異量,相關系數才能顯而易見。如樣本中的數學成績非常接近(如都是95分左右),則數學成績差異大部分是測量誤差引起的,則數學成績與其它變量之間的相關就不***。
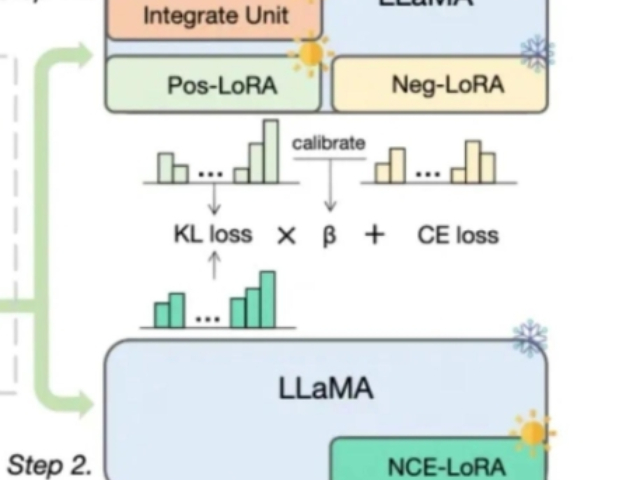
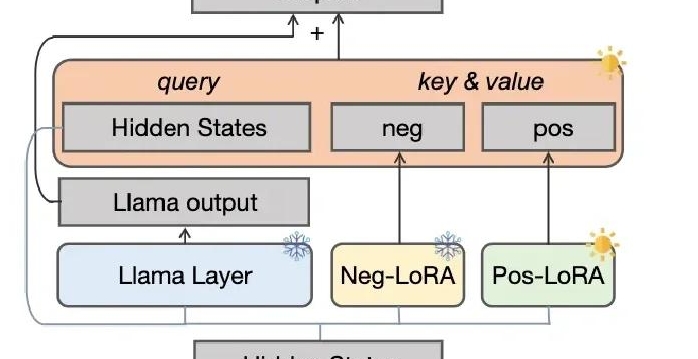
驗證模型是機器學習和統計建模中的一個重要步驟,旨在評估模型的性能和泛化能力。以下是一些常見的模型驗證方法:訓練集和測試集劃分:將數據集分為訓練集和測試集,通常按70%/30%或80%/20%的比例劃分。模型在訓練集上進行訓練,然后在測試集上評估性能。交叉驗證:K折交叉驗證:將數據集分為K個子集,模型在K-1個子集上訓練,并在剩下的一個子集上測試。這個過程重復K次,每次選擇不同的子集作為測試集,***取平均性能指標。留一交叉驗證(LOOCV):每次只留一個樣本作為測試集,其余樣本作為訓練集,適用于小數據集。驗證過程可以幫助我們識別和減少過擬合的風險。

構建模型:在訓練集上構建模型,并進行必要的調優和參數調整。驗證模型:在驗證集上評估模型的性能,并根據評估結果對模型進行調整和優化。測試模型:在測試集上測試模型的性能,以驗證模型的穩定性和可靠性。解釋結果:對驗證和測試的結果進行解釋和分析,評估模型的優缺點和改進方向。四、模型驗證的注意事項在進行模型驗證時,需要注意以下幾點:避免數據泄露:確保驗證集和測試集與訓練集完全**,避免數據泄露導致驗證結果不準確。留一交叉驗證(LOOCV):每次只留一個樣本作為測試集,其余樣本作為訓練集,適用于小數據集。浦東新區優良驗證模型便捷
使用驗證集評估模型的性能,常用的評估指標包括準確率、召回率、F1分數、均方誤差(MSE)、均方根誤差。虹口區優良驗證模型咨詢熱線
驗證模型是機器學習過程中的一個關鍵步驟,旨在評估模型的性能,確保其在實際應用中的準確性和可靠性。驗證模型通常包括以下幾個步驟:數據準備:數據集劃分:將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調整模型參數(如超參數調優),測試集用于**終評估模型性能。數據預處理:包括數據清洗、特征選擇、特征縮放等,確保數據質量。模型訓練使用訓練數據集對模型進行訓練,得到初始模型。根據需要調整模型的參數和結構,以提高模型在訓練集上的性能。虹口區優良驗證模型咨詢熱線
上海優服優科模型科技有限公司在同行業領域中,一直處在一個不斷銳意進取,不斷制造創新的市場高度,多年以來致力于發展富有創新價值理念的產品標準,在上海市等地區的商務服務中始終保持良好的商業口碑,成績讓我們喜悅,但不會讓我們止步,殘酷的市場磨煉了我們堅強不屈的意志,和諧溫馨的工作環境,富有營養的公司土壤滋養著我們不斷開拓創新,勇于進取的無限潛力,上海優服優科模型科技供應攜手大家一起走向共同輝煌的未來,回首過去,我們不會因為取得了一點點成績而沾沾自喜,相反的是面對競爭越來越激烈的市場氛圍,我們更要明確自己的不足,做好迎接新挑戰的準備,要不畏困難,激流勇進,以一個更嶄新的精神面貌迎接大家,共同走向輝煌回來!
- 上海銷售工程樣車試制信息中心 2025-12-19
- 青浦區優良汽車設計開發價目 2025-12-19
- 靜安區直銷汽車設計開發價目 2025-12-19
- 閔行區直銷汽車設計開發供應 2025-12-19
- 上海自動驗證模型平臺 2025-12-19
- 普陀區口碑好工程樣車試制訂制價格 2025-12-19
- 楊浦區優良工程樣車試制便捷 2025-12-19
- 徐匯區銷售汽車設計開發優勢 2025-12-19
- 靜安區優良展示車加工優勢 2025-12-19
- 閔行區自動汽車設計開發便捷 2025-12-19
- 長寧區品牌裝卸搬運好處 2025-12-19
- 中山工業制造erp系統教程 2025-12-19
- 太倉抖音運營答疑解惑 2025-12-19
- 靜安區第三方會議及展覽服務介紹 2025-12-19
- 杭州疑難核名服務代理記賬條件 2025-12-19
- 珠海重型設備物流服務方案 2025-12-19
- 青少年糾正教育 2025-12-19
- 斯里蘭卡紡織展會參展須知 2025-12-19
- 長寧區企業形象策劃費用 2025-12-19
- 寶山區一站式保潔服務服務電話 2025-12-19