長寧區自動驗證模型價目
三、面臨的挑戰與應對策略數據不平衡:當數據集中各類別的樣本數量差異很大時,驗證模型的準確性可能會受到影響。解決方法包括使用重采樣技術(如過采樣、欠采樣)或應用合成少數類過采樣技術(SMOTE)來平衡數據集。時間序列數據的特殊性:對于時間序列數據,簡單的隨機劃分可能導致數據泄露,即驗證集中包含了訓練集中未來的信息。此時,應采用時間分割法,確保訓練集和驗證集在時間線上完全分離。模型解釋性:在追求模型性能的同時,也要考慮模型的解釋性,尤其是在需要向非技術人員解釋預測結果的場景下。通過集成學習中的bagging、boosting方法或引入可解釋性更強的模型(如決策樹、線性回歸)來提高模型的可解釋性。數據集劃分:將數據集劃分為訓練集、驗證集和測試集。長寧區自動驗證模型價目
靈敏度分析:這種方法著重于確保模型預測值不會背離期望值。如果預測值與期望值相差太大,可以判斷是否需要調整模型或期望值。此外,靈敏度分析還能確保模型與假定條件充分協調。擬合度分析:類似于模型標定,這種方法通過比較觀測值和預測值的吻合程度來評估模型的性能。由于預測的規劃年數據不可能在現場得到,因此需要借用現狀或過去的觀測值進行驗證。具體做法包括將觀測數據按時序分成前后兩組,前組用于標定,后組用于驗證;或將同時段的觀測數據隨機地分為兩部分,用***部分數據標定后的模型計算值同第二部分數據相擬合。長寧區自動驗證模型價目常見的有K折交叉驗證,將數據集分為K個子集,輪流使用其中一個子集作為測試集,其余作為訓練集。
交叉驗證:交叉驗證是一種常用的內部驗證方法,它將數據集拆分為多個相等大小的子集,然后重復進行模型構建和驗證的步驟。每次選用其中的一個子集用于評估模型性能,其他所有的子集用來構建模型。這種方法可以確保模型驗證時使用的數據是模型擬合過程中未使用的數據,從而提高驗證的可靠性。Bootstrapping法:在這種方法中,原始數據集被隨機抽樣數百次(有放回)用來創建相同大小的多個數據集。然后,在這些數據集上分別構建模型并評估性能。這種方法可以提供對模型性能的穩健估計。
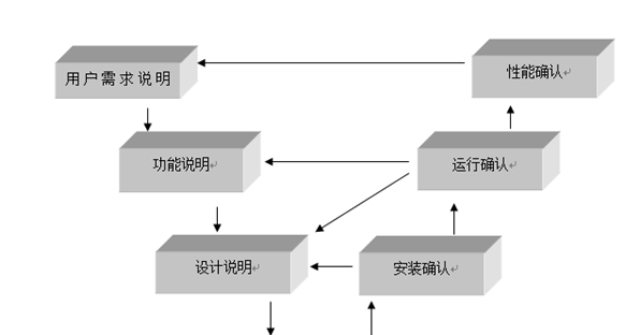
4.容許更大彈性的測量模型傳統上,只容許每一題目(指標)從屬于單一因子,但結構方程分析容許更加復雜的模型。例如,我們用英語書寫的數學試題,去測量學生的數學能力,則測驗得分(指標)既從屬于數學因子,也從屬于英語因子(因為得分也反映英語能力)。傳統因子分析難以處理一個指標從屬多個因子或者考慮高階因子等有比較復雜的從屬關系的模型。5.估計整個模型的擬合程度在傳統路徑分析中,只能估計每一路徑(變量間關系)的強弱。在結構方程分析中,除了上述參數的估計外,還可以計算不同模型對同一個樣本數據的整體擬合程度,從而判斷哪一個模型更接近數據所呈現的關系。 [2]將不同模型的性能進行比較,選擇表現模型。

驗證模型是機器學習過程中的一個關鍵步驟,旨在評估模型的性能,確保其在實際應用中的準確性和可靠性。驗證模型通常包括以下幾個步驟:數據準備:數據集劃分:將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調整模型參數(如超參數調優),測試集用于**終評估模型性能。數據預處理:包括數據清洗、特征選擇、特征縮放等,確保數據質量。模型訓練使用訓練數據集對模型進行訓練,得到初始模型。根據需要調整模型的參數和結構,以提高模型在訓練集上的性能。將驗證和優化后的模型部署到實際應用中。上海自動驗證模型要求
繪制學習曲線可以幫助理解模型在不同訓練集大小下的表現,幫助判斷模型是否過擬合或欠擬合。長寧區自動驗證模型價目
確保準確性:驗證模型在特定任務上的預測或分類準確性是否達到預期。提升魯棒性:檢查模型面對噪聲數據、異常值或對抗性攻擊時的穩定性。公平性考量:確保模型對不同群體的預測結果無偏見,避免算法歧視。泛化能力評估:測試模型在未見過的數據上的表現,以預測其在真實世界場景中的效能。二、模型驗證的主要方法交叉驗證:將數據集分成多個部分,輪流用作訓練集和測試集,以***評估模型的性能。這種方法有助于減少過擬合的風險,提供更可靠的性能估計。長寧區自動驗證模型價目
上海優服優科模型科技有限公司在同行業領域中,一直處在一個不斷銳意進取,不斷制造創新的市場高度,多年以來致力于發展富有創新價值理念的產品標準,在上海市等地區的商務服務中始終保持良好的商業口碑,成績讓我們喜悅,但不會讓我們止步,殘酷的市場磨煉了我們堅強不屈的意志,和諧溫馨的工作環境,富有營養的公司土壤滋養著我們不斷開拓創新,勇于進取的無限潛力,上海優服優科模型科技供應攜手大家一起走向共同輝煌的未來,回首過去,我們不會因為取得了一點點成績而沾沾自喜,相反的是面對競爭越來越激烈的市場氛圍,我們更要明確自己的不足,做好迎接新挑戰的準備,要不畏困難,激流勇進,以一個更嶄新的精神面貌迎接大家,共同走向輝煌回來!
- 靜安區直銷汽車設計開發價目 2025-12-19
- 上海自動驗證模型平臺 2025-12-19
- 徐匯區銷售汽車設計開發優勢 2025-12-19
- 靜安區優良展示車加工優勢 2025-12-19
- 閔行區自動汽車設計開發便捷 2025-12-19
- 黃浦區優良驗證模型便捷 2025-12-19
- 普陀區正規汽車設計開發要求 2025-12-19
- 嘉定區智能展示車加工便捷 2025-12-18
- 崇明區正規工程樣車試制平臺 2025-12-18
- 金山區直銷汽車設計開發優勢 2025-12-18
- 鶴壁工廠規劃方法論 2025-12-19
- 全方面GEO生成式引擎優化答疑解惑 2025-12-19
- 泉州自動化互聯網推廣推廣 2025-12-19
- 嘉定區本地市場營銷策劃五星服務 2025-12-19
- 崇明區電話智力游戲開發聯系方式 2025-12-19
- 河南拖車銷售 2025-12-19
- 河南主題廣告畫面印刷設計 2025-12-19
- 蘇州上門專利轉讓哪個好 2025-12-19
- 鹽田區人工智能專利申請答復 2025-12-19
- 六合區PTI試驗粉塵有哪些 2025-12-19